
BigQuery テーブル更新トリガで、Dataplex のプロファイリングを実行してみた。
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、みかみです。
昨日の夜、犬の散歩してたら、ホタルを見かけました。
ホタルといえば初夏なイメージでしたが、沖縄は秋にもホタルが現れるようで、ちょっと得した気分です。
やりたいこと
- Dataform から BigQuery マートテーブル作成時に、Dataplex のデータプロファイリングを自動で実行したい。
- Cloud Run 関数(旧 Cloud Functions)から Dataplex のデータプロファイリングを実行したい。
- BigQuery のテーブルが再作成されたら、Cloud Run 関数(旧 Cloud Functions)を実行したい。
- 監査ログ(データアクセスログ)イベントをトリガに、Cloud Run 関数(旧 Cloud Functions)を実行したい。
図にするとこんな感じ。
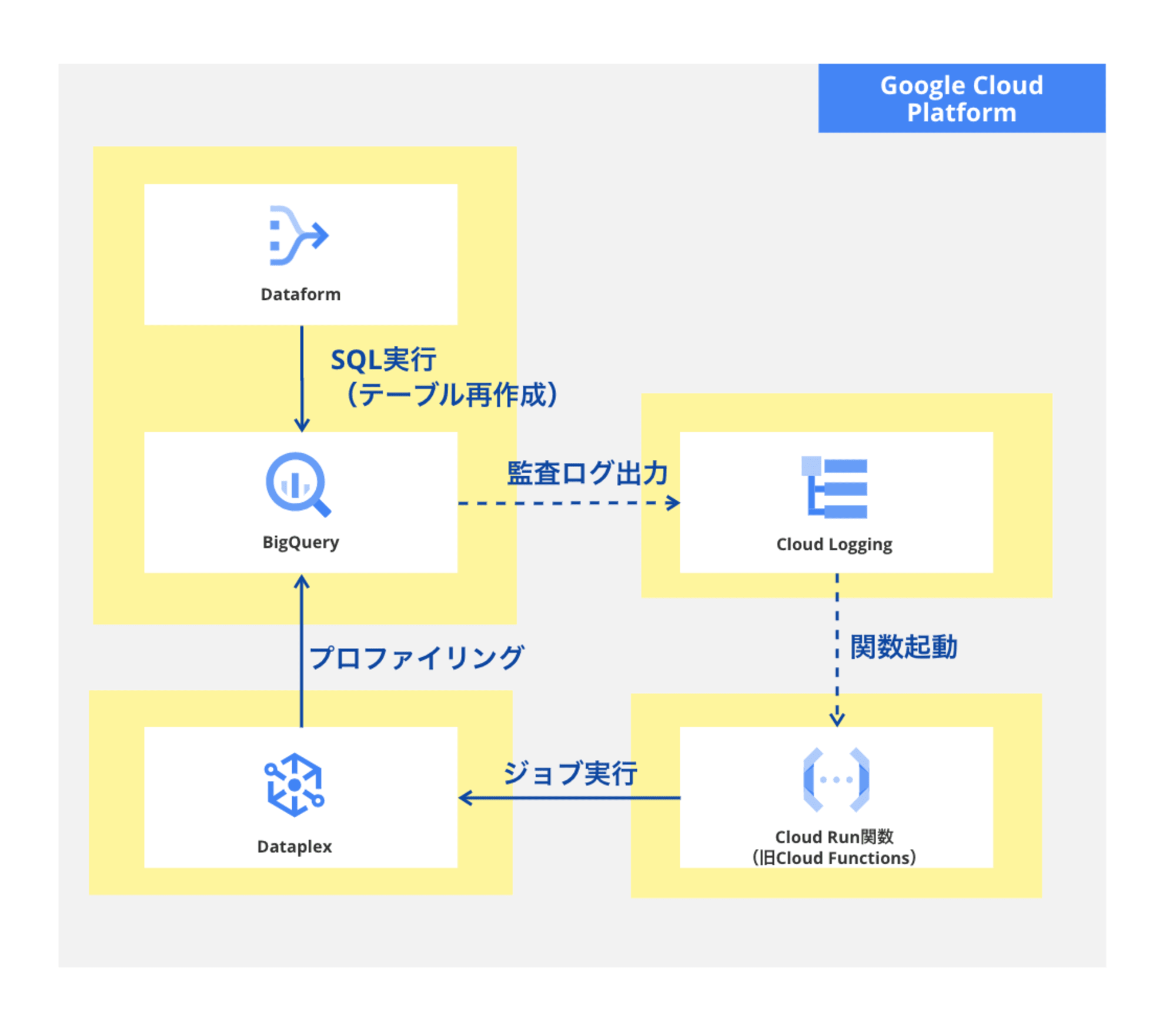
BigQuery テーブル再作成時に発生する監査ログ(データアクセス監査ログ)をトリガにCloud Run 関数(旧 Cloud Functions)を起動して、Cloud Run 関数から Dataplex のプロファイリングを実行します。
前提
Google Cloud SDK(gcloud コマンド)の実行環境は準備済みであるものとします。 本エントリでは、Cloud Shell を使用しました。
また、BigQuery や Dataplex など各サービス操作に必要な API の有効化と必要な権限は付与済みです。
なお、文中、プロジェクトIDなど一部の文字は伏字に変更しています。
Dataplex と Dataform
本エントリでは、Dataplex GUI からのプロファイリング実行や、Dataform の実装に関しては言及しておりません。
Google Cloud のデータ管理サービス Dataplex では、BigQuery テーブルデータのプロファイリングや品質チェックなど、データの管理を行うことができます。
また、Dataform は、SQLX という拡張SQL言語を使用して、SQL レイヤのデータ変換やモデリング、テーブル依存関係を自動解決してくれるサービスです。
dbt をご存知の方でしたら、dbt と同様の位置付けのサービスと言うとわかりやすいと思います。
Dataform を使うと、GUI からデータリネージが確認できたり、タグ指定で実行範囲を指定できたりするので、データパイプラインを効率的に開発、管理することができます。
Dataform で全件洗い替えでテーブルデータを作成する場合、TRUNCATE + INSERT ではなく、CREATE OR REPLACE TABLE の SQL が発行されます。
既存テーブルが REPLACE された場合、Dataplex から付与済みのビジネスメタデータはどうなるの?(もしかして、Dataform と Dataplex は相性悪い?!
と思い検証したところ、タグ情報やビジネス用語などはそのまま維持されましたが、データプロファイリングや品質チェック結果はクリアされてしまいました。(テーブルデータが変更されたので当然といえば当然ですね。
Dataform 利用有無にかかわらず、テーブルデータの追加や洗い替えのタイミングでデータのプロファイリングや品質チェックを再実行できれば、データ管理の精度が上がります。
とはいえ、デーリーバッチで複数テーブルのデータを更新している場合などには、手動で再実行する運用は現実的ではありません。。
ということで。
Cloud Run 関数をデプロイ
Cloud Run 関数実行用サービスアカウントを作成
以下のコマンドで、Cloud Run 関数実行用のサービスアカウントを作成して、必要なロールを付与しました。
gcloud iam service-accounts create sa-functions \
--display-name "Functions実行用サービスアカウント"
gcloud projects add-iam-policy-binding [PROJECT_ID] \
--member="serviceAccount:sa-functions@[PROJECT_ID].iam.gserviceaccount.com" \
--role="roles/run.invoker"
gcloud projects add-iam-policy-binding [PROJECT_ID] \
--member="serviceAccount:sa-functions@[PROJECT_ID].iam.gserviceaccount.com" \
--role="roles/eventarc.eventReceiver"
gcloud projects add-iam-policy-binding [PROJECT_ID] \
--member="serviceAccount:sa-functions@[PROJECT_ID].iam.gserviceaccount.com" \
--role="roles/dataplex.admin"
gcloud projects add-iam-policy-binding [PROJECT_ID] \
--member="serviceAccount:sa-functions@[PROJECT_ID].iam.gserviceaccount.com" \
--role="roles/bigquery.admin"
Python コードを準備
以下のPythonコードを、main.py というファイル名で保存しました。
from google.cloud import dataplex_v1
import functions_framework
import os
import time
def run_data_scan(project_id, location, data_scan_id, data_source_entity):
client = dataplex_v1.DataScanServiceClient()
parent = f"projects/{project_id}/locations/{location}"
data_scan_name = f"{parent}/dataScans/{data_scan_id}"
# データスキャンジョブが既に存在するか確認
existing_scans = client.list_data_scans(parent=parent)
scan_exists = any(scan.name == data_scan_name for scan in existing_scans)
if not scan_exists:
# 同名のジョブが存在しない場合はデータスキャンジョブを作成
data_scan = dataplex_v1.DataScan(
data=dataplex_v1.DataSource(
entity=data_source_entity
),
data_profile_spec=dataplex_v1.DataProfileSpec(
sampling_percent=10
)
)
request = dataplex_v1.CreateDataScanRequest(
parent=parent,
data_scan_id=data_scan_id,
data_scan=data_scan
)
operation = client.create_data_scan(request=request)
print("[functions] Waiting for operation to complete...")
response = operation.result()
print(f"[functions] Data scan created: {response.name}")
else:
print(f"[functions] Data scan with ID '{data_scan_id}' already exists.")
# データスキャンジョブを実行
run_request = dataplex_v1.RunDataScanRequest(name=data_scan_name)
run_response = client.run_data_scan(request=run_request)
name = run_response.job.name
print(f"[functions] Data scan job started: {name}")
# データスキャンジョブのステータスをポーリングして確認
while True:
job = client.get_data_scan_job(name=name)
if job.state == dataplex_v1.DataScanJob.State.SUCCEEDED:
return True
elif job.state == dataplex_v1.DataScanJob.State.FAILED:
print(f"[functions] error: {job.error.message}")
return False
else:
print("[functions] Waiting for data scan to complete...")
time.sleep(30) # 30秒待機
@functions_framework.cloud_event
def main(cloudevent):
print(f"Event type: {cloudevent['type']}")
if 'subject' in cloudevent:
print(f"Subject: {cloudevent['subject']}")
# 環境変数チェック
PROJECT_ID = os.getenv('PROJECT_ID')
SA_DATAFORM = os.getenv('SA_DATAFORM')
LOCATION = os.getenv('LOCATION')
LAKE_ID = os.getenv('LAKE_ID')
ZONE_ID = os.getenv('ZONE_ID')
if not PROJECT_ID or not SA_DATAFORM or not LOCATION or not LAKE_ID or not ZONE_ID:
raise Exception('Invalid env val.')
# イベントデータチェック
payload = cloudevent.data.get("protoPayload")
if not payload:
return
principalEmail = payload.get('authenticationInfo', {}).get('principalEmail', None)
if principalEmail != SA_DATAFORM:
# Dataformからのクエリじゃない場合は処理せず終了
return
jobChange = payload.get('metadata', {}).get('jobChange', None)
if not jobChange:
return
statementType = jobChange.get('job', {}).get('jobConfig', {}).get('queryConfig', {}).get('statementType', None)
if statementType != 'CREATE_TABLE_AS_SELECT':
return
statementType = jobChange.get('job', {}).get('jobConfig', {}).get('queryConfig', {}).get('statementType', None)
destinationTable = jobChange.get('job', {}).get('jobConfig', {}).get('queryConfig', {}).get('destinationTable', None)
dst_dataset = destinationTable.split('/')[3]
dst_table = destinationTable.split('/')[5]
print(f'[functions] dst_dataset: {dst_dataset} / dst_table: {dst_table}')
entity_id = dst_table
data_scan_id = f"scan-{entity_id.replace('_', '-')}"
data_source_entity = f"projects/{PROJECT_ID}/locations/{LOCATION}/lakes/{LAKE_ID}/zones/{ZONE_ID}/entities/{entity_id}"
run_result = run_data_scan(PROJECT_ID, LOCATION, data_scan_id, data_source_entity)
if run_result:
print("[functions] Data scan completed successfully.")
else:
print(f"[functions] Data scan failed...")
まず、プロジェクト名や Dataplex のレイク名など、データプロファイリング実行に必要な情報を環境変数から取得し、トリガイベントの監査ログ内容をチェックします。
今回は Dataform からの SQL 実行を対象としているので、監査ログ内 principalEmail(実行元情報)が Dataform 実行用サービスアカウントではない場合は処理せず終了します。
また、実行された BigQuery ジョブ(SQL)の statementType が CREATE_TABLE_AS_SELECT ではない場合は、全件洗い替えのケースではないので処理せず終了します。
Dataform からのテーブル再作成イベントだった場合は、dataplex_v1 ライブラリを使用して、データスキャンジョブの存在チェックを行い、ジョブが存在していない場合は作成してから実行、すでにある場合には既存ジョブを実行します。
検証で使用している BigQuery テーブルはデータ件数が10件ほどの小さいものなので、スキャンが完了するまで30秒間隔でポーリングして待機していますが、データが多い場合には、関数のタイムアウトやコンピューティングコスト増加の懸念があるので、管理アクティビティ監査ログをトリガに起動する別関数を実装するなどご検討ください。
また、以下を requirements.txt というファイル名で保存しました。
functions-framework==3.*
google-cloud-dataplex>=2.2.2
デプロイ
先ほどのファイルを保存したのと同じディレクトリで、以下のコマンドを実行して Cloud Run 関数(旧 Cloud Functions)をデプロイしました。
gcloud functions deploy exec_profiling \
--gen2 \
--region asia-northeast1 \
--runtime python312 \
--entry-point=main \
--trigger-event-filters="type=google.cloud.audit.log.v1.written" \
--trigger-event-filters="serviceName=bigquery.googleapis.com" \
--trigger-event-filters="methodName=google.cloud.bigquery.v2.JobService.InsertJob" \
--trigger-location=asia-northeast1 \
--service-account=sa-functions@[PROJECT_ID].iam.gserviceaccount.com \
--trigger-service-account=sa-functions@[PROJECT_ID].iam.gserviceaccount.com \
--set-env-vars PROJECT_ID=[PROJECT_ID],SA_DATAFORM=service-[PROJECT_NO]@gcp-sa-dataform.iam.gserviceaccount.com,LOCATION=asia-northeast1,LAKE_ID=lake-tokyo,ZONE_ID=marketing
実行
Dataform のコードを実行して、意図通り Cloud Run 関数が実行されて Dataplex のプロファイリングが実行されるか確認してみます。
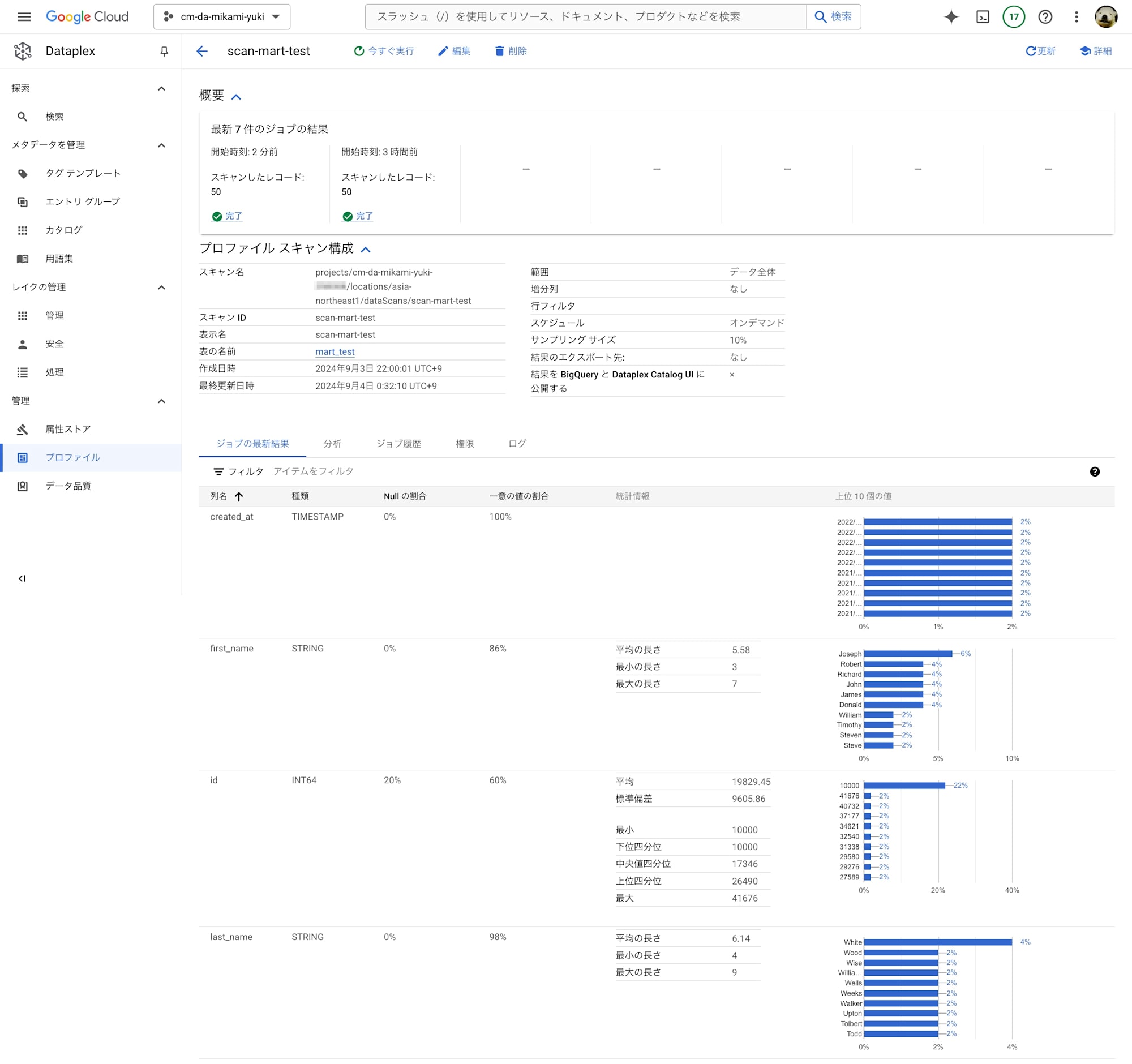
Clouf Run 関数ログから、プロファイリングが正常終了したことが確認できました。

Dataplex プロファイル画面からも、ジョブが再実行されたことが確認できました。
つまづいたところ
Cloud Run 関数デプロイエラー
はじめ、Cloud Run 関数(旧 Cloud Functions)デプロイ時に、CLI コマンド実行で以下のエラーが発生しました。
(省略)
ERROR: (gcloud.functions.deploy) OperationError: code=3, message=Could not create or update Cloud Run service exec-profiling, Container Healthcheck failed. Revision 'exec-profiling-00003-pid' is not ready and cannot serve traffic. The user-provided container failed to start and listen on the port defined provided by the PORT=8080 environment variable. Logs for this revision might contain more information.
(省略)
For more troubleshooting guidance, see https://cloud.google.com/run/docs/troubleshooting#container-failed-to-start
8080 ポートが開いていない?
もしかして、Cloud Functions から Cloud Run 関数になったことで、gcloud コマンドの仕様が変わった?
やっぱ gcloud run コマンドでデプロイしないとダメ?
などと思い、しばし調べてみましたが、なんのことはなく --entry-point で指定したメイン関数名が不正だっただけというケアレスミスでした。。
(「エントリーポイントが見つかりません」みたいなエラーメッセージ出てくれると嬉しいなぁw
データプロファイリングジョブ新規作成エラー
はじめ、Cloud Run 関数実行用サービスアカウントに、BigQuery 管理者ロール(roles/bigquery.admin)を付与していませんでした。
既存のデータプロファイリングジョブを実行する場合は問題なかったのですが、ジョブを新規作成するケースで以下のエラーが発生しました。
google.api_core.exceptions.PermissionDenied: 403 Permission denied for user to access source BigQuery table 'mart_test'. You need to have `bigquery.tables.get` permission for the specified table to create a DataScan for it."
今回は検証目的のため BigQuery 管理者ロールを付与していますが、本番運用時には「管理者」は過剰な権限ではないかと思うので、ご承知おきください。
補足
本エントリで記載しているコードでは、プロファイリングの実行はできましたが、Dataplex > 検索メニューから対象テーブルを選択後の画面の「データプロファイル」タブには結果が反映されません。
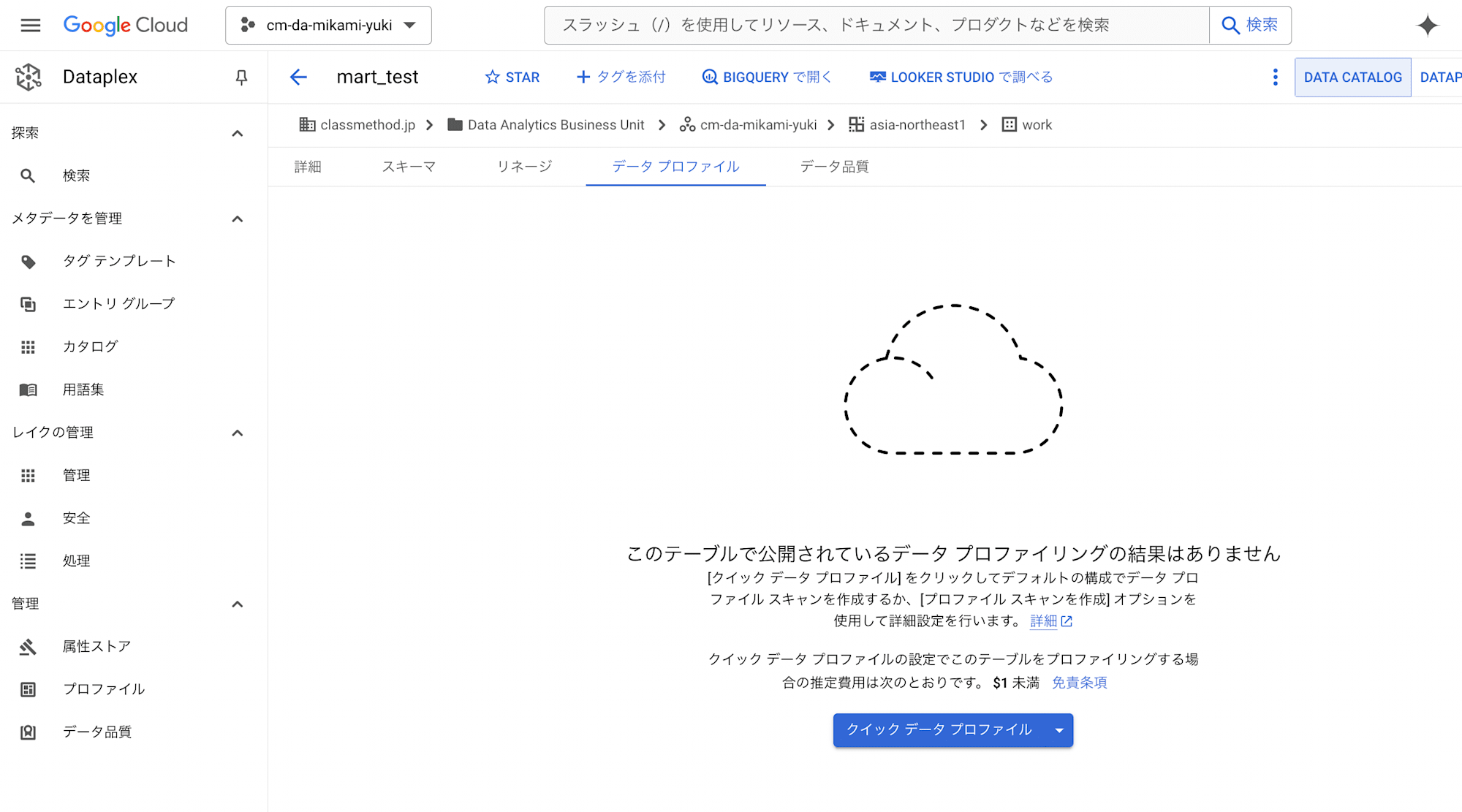
プロファイリングジョブの公開設定が有効になっていないためです。
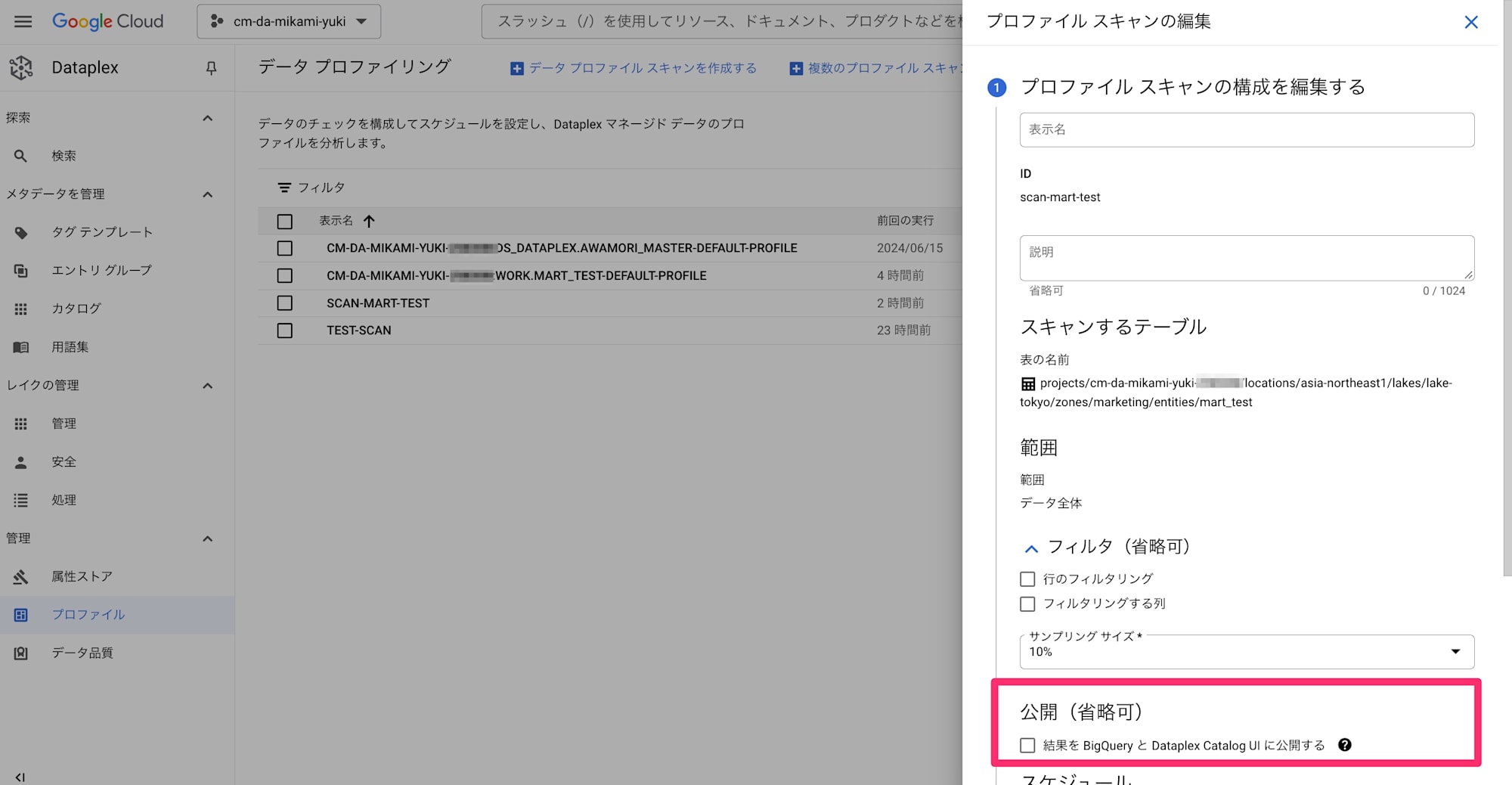
実運用ではテーブル検索からプロファイリングを確認することが多いと思うので、Python ライブラリからの公開設定コードの検証取れましたら、本エントリにも追記します。
(2024/09/09 追記)
Dataform 実行でプロファイリング結果が「データプロファイル」タブに反映されない原因は、BigQuery テーブルの Dataplex ラベルを消してしまっていたためでした。
Dataplex プロファイリングジョブの公開設定を有効にすると、以下のラベルが対象テーブルに自動で付与されます。
dataplex-dp-published-scan : [SCAN_ID]dataplex-dp-published-project : [PROJECT_ID]dataplex-dp-published-location : [LOCATION]
Cloud Run 関数で、スキャン実行後に BigQuery テーブルにラベルを付与する以下のコードを追加したところ、スキャン結果が「データプロファイル」タブに反映されることを確認できました。
from google.cloud import bigquery
def add_label_table(project_id, location, data_scan_id, dataset_id, table_id):
label_key_scan = "dataplex-dp-published-scan"
label_key_project = "dataplex-dp-published-project"
label_key_location = "dataplex-dp-published-location"
client = bigquery.Client()
dataset_ref = bigquery.DatasetReference(project_id, dataset_id)
table_ref = dataset_ref.table(table_id)
table = client.get_table(table_ref)
print(table.labels)
if label_key_scan in table.labels and label_key_project in table.labels and label_key_location in table.labels:
print('Label is already attached.')
return
table.labels = {
label_key_scan: f"{data_scan_id}",
label_key_project: f"{project_id}",
label_key_location: f"{location}"
}
table = client.update_table(table, ["labels"])
print("Labels added to {}".format(table_id))
(省略)
def main(cloudevent):
(省略)
add_label_table(PROJECT_ID, LOCATION, data_scan_id, dst_dataset, dst_table)
※requirements.txt にも、BigQuery クライアントライブラリを追加(google-cloud-bigquery>=3.25.0)しました。
まとめ(所感)
余談ですが、最近 Cloud Functions から Cloud Run 関数になった Google Cloud の FaaS サービスのデプロイに、本当にこれまでと同様の gcloud functions deploy コマンドが使えるのかちょっと気になっていましたが、問題なくデプロイできることが確認できました。
また、Dataplex プロファイリング設定手順の 公式ドキュメントには REST I/F が 「Not supported.」の記載もあり、また Google Cloud Python Client Library のサンプルコードには Dataplex のコードが見当たらなかったので、「もしかして Python Client Library 非対応?!」とドキドキしたりしましたが、Python コードからもちゃんと Dataplex の操作が実行できました。
今回は、BigQuery のテーブル再作成をトリガに Dataplex のプロファイリングを実行してみましたが、テーブルデータ INSERT をトリガにしたり、マスキングなど別の処理を実行したり、BigQuery のテーブルデータ変更を起因に後続処理を自動実行できたら便利なケースは他にもあるのではないかと思います。
また、データアクセス監査ログ意外にも、特定のアクティビティ監査ログを起因に後続処理を実行するなど、システム要件に合わせて柔軟な実装が可能だと思います。
特にデータ分析業務においては、BigQuery のデータ更新イベントをトリガに後続処理を自動実行することにより、業務の効率化が期待できるとともに、より快適な分析環境になるのではないかと思いました。










